Rolling Your Own
You’ve probably already heard about XML, Extensible Markup Language - it’s been the subject of many water-cooler conversations over the past three years. If you’re a developer, you may even have tried your hand at creating an XML document, complete with user-defined tags and markup, and you’ve probably also tried using a single marked-up XML data source to generate documents in HTML, WML or other formats.
Over the next few pages, I’m going to bring XML into the ASP.NET world, with an explanation of how you can use ASP.NET code to read your XML data and convert it into browser-readable HTML. I’ll also spend some time explaining the DOM technique used to parse XML data, together with illustrations of how the .NET implementation of this works.
I’ll try and keep it simple - I’m going to use very simple XML sources, so you don’t have to worry about namespaces, DTDs and PIs - although I will assume that you know the basic rules of XML markup, and of ASP.NET scripting.
Let’s get started!
Hungry Eyes
ASP.NET uses the Document Object Model (DOM) to parse an XML document. DOM builds a tree representation of the XML data structures in the document, and then offers built-in methods to navigate through this tree. Once a particular node has been reached, built-in properties can be used to obtain the value of the node, and use it within the script.
To illustrate this, I’ll begin with something simple. Consider the following XML file, a XML-encoded menu for the friendly neighbourhood fast-food joint.
<menu>
<item id="1">
<name>Hamburger</name>
<price currency="USD">1</price>
<size units="oz">3.70</size>
</item>
<item id="2">
<name>French Fries</name>
<price currency="USD">1.2</price>
<size units="oz">3.20</size>
</item>
<item id="3">
<name>Apple Pie</name>
<price currency="USD">1.5</price>
<size units="oz">7.80</size>
</item>
</menu>
Now, I need to parse this so that I can use the data within the elements. Here’s a simple ASP.NET script that initializes the parser and reads the XML file.
<%@ Page Language="C#"%>
<%@ import namespace="System.Xml"%>
<html>
<head>
<script runat="server">
void NodeDetails(XmlNode objNode) {
// print details of the root element
output.Text = "Node Name: " + objNode.Name + "<br />";
output.Text += "Node Type: " + objNode.NodeType + "<br />";
// check if the Element has child nodes
if(objNode.HasChildNodes) {
output.Text += "Node Name: " + objNode.FirstChild.Name + "<br />";
output.Text += "Node Type: " + objNode.FirstChild.NodeType + "<br />";
}
}
void Page_Load() {
// location of XML file
string strXmlDoc = "http://localhost:2121/xml/menu.xml";
// create an instance of XmlDocument object
XmlDocument objXmlDoc = new XmlDocument();
// load the XML file into the XmlDocument object
objXmlDoc.Load(strXmlDoc);
// access the root element of the XML file
XmlElement objRootElem = objXmlDoc.DocumentElement;
// get details about the root node and its children
NodeDetails(objRootElem);
}
</script>
</head>
<body>
<asp:label id="output" runat="server" />
</body>
</html>
Load this example in your browser to get the following output.

Now, this might not look like much, but it demonstrates the basic concept of the DOM, and builds the foundation for more complex code. Let’s look at the code in detail:
- The first step is to import all the classes required to execute the application. First come the .NET libraries for the XML parser.
<%@ import namespace="System.Xml"%>
- Within the Page_Load() function, I start by defining some variables and objects. The first is a string variable to store the location of the XML file, and the second is a local instance of the XMLDocument object.
<%
// location of XML file
string strXmlDoc = "http://localhost:2121/xml/menu.xml";
// create an instance of XmlDocument object
XmlDocument objXmlDoc = new XmlDocument();
%>
- The next step is to load the XML file in memory - this is possible using the Load() method of the XmlDocument object. The end result of this process is a DOM tree consisting of a single root and its child nodes, each of which exposes methods that describe the object in greater detail.
<%
// load the XML file into the XmlDocument object
objXmlDoc.Load(strXmlDoc);
%>
- To get to the root of the DOM tree, I’ve used the “DocumentElement” property of the XmlDocument object. - this useful property always returns the root element of an XML file.
<%
// access the root element of the XML file
XmlElement objRootElem = objXmlDoc.DocumentElement;
%>
- Once a reference to a node has been obtained, a number of properties become available to obtain the name and value of that node, as well as references to parent and child nodes. In the code snippet below, I’ve used the “NodeType” and “Name” properties of the XmlNode object to obtain the type and name of the node respectively. Similarly, the HasChildNodes() method can be used to find out if a node has child nodes under it, while the “FirstChild” property can be used to get a reference to the first child node.
<%
void NodeDetails(XmlNode objNode) {
// print details of the root element
output.Text = "Node Name: " + objNode.Name + "<br />";
output.Text += "Node Type: " + objNode.NodeType + "<br />";
// check if the Element has child nodes
if(objNode.HasChildNodes) {
output.Text += "Node Name: " + objNode.FirstChild.Name + "<br />";
output.Text += "Node Type: " + objNode.FirstChild.NodeType + "<br />";
}
}
%>
If you’re sharp-eyed, you’ll notice that the “DocumentElement” property returns an object of class XmlElement, whereas my NodeDetails() function above accepts a XmlNode object as a input parameter. The reason is simple: the XmlElement object inherits all the methods and properties of the XmlNode object, as is clear from the documentation available at the following URL: http://msdn.microsoft.com/library/en-us/cpref/html/frlrfsystemxmlxmlelementclasstopic.asp?frame=true. Hence, all XmlElement objects can be cast (implicitly) as XmlNode objects (though the reverse is not true).
Delving Deeper
As you must have figured out by now, using the DOM parser is fairly easy - essentially, it involves creating a “tree” of the elements in the XML document, and traversing that tree with built-in methods. In the introductory example, I ventured as far as the document element; in this next one, I’ll go much further, demonstrating how the parser’s built-in methods can be used to navigate to any point in the document tree.
<%@ Page Language="C#"%>
<%@ import namespace="System.Xml"%>
<html>
<head>
<script runat="server">
void NodeDetails(XmlNode objNode) {
// print details of the root element
output.Text = "Node Name: " + objNode.Name + "<br />";
// check if the element has child nodes
if(objNode.HasChildNodes) {
// get the list of child nodes
XmlNodeList objChildren = objNode.ChildNodes;
// loop through the Nodes
for(int count = 0; count < objChildren.Count; count++) {
output.Text += " Node Name: " + objChildren[count].Name + "<br />";
// check for children
if(objChildren[count].HasChildNodes) {
// get the list of child nodes
XmlNodeList objChildrenOfChildren = objChildren[count].ChildNodes;
// loop through the Nodes
for(int innercount = 0; innercount < objChildrenOfChildren.Count; innercount++) {
output.Text += " Node Name: " + objChildrenOfChildren[innercount].Name + "<br />";
}
}
}
}
}
void Page_Load() {
// location of XML file
string strXmlDoc = "http://localhost:2121/xml/menu.xml";
// create an instance of XmlDocument object
XmlDocument objXmlDoc = new XmlDocument();
// load XML document in XmlDocument object
objXmlDoc.Load(strXmlDoc);
// get the root element
XmlElement objRootElem = objXmlDoc.DocumentElement;
// get more details about the node
NodeDetails(objRootElem);
}
</script>
</head>
<body>
<asp:label id="output" runat="server" />
</body>
</html>
Here’s the output.

As demonstrated in the first example, the fundamentals remain unchanged - create an instance of an XmlDocument object, load an XML document, get a reference to the root of the tree and start traversing the tree. Consequently, most of the code here remains the same as that used in the introductory example, with the changes occurring only in the NodeDetails() function. Let’s take a closer look at this function:
void NodeDetails(XmlNode objNode) {
// print details of the root element
output.Text = "Node Name: " + objNode.Name + "<br />";
// check if the element has child nodes
if(objNode.HasChildNodes) {
// get the list of child nodes
XmlNodeList objChildren = objNode.ChildNodes;
// loop through the Nodes
for(int count = 0; count < objChildren.Count; count++) {
output.Text += " Node Name: " + objChildren[count].Name + "<br />";
// check for children
if(objChildren[count].HasChildNodes) {
// get the list of child nodes
XmlNodeList objChildrenOfChildren = objChildren[count].ChildNodes;
// loop through the Nodes
for(int innercount = 0; innercount < objChildrenOfChildren.Count; innercount++) {
output.Text += " Node Name: " + objChildrenOfChildren[innercount].Name + "<br />";
}
}
}
}
}
Once a reference to the root of the tree has been obtained and passed to NodeDetails(), the “ChildNodes” property is used to obtain a list of the children of that node. This list is returned as a new XmlNodeList object, which comes with its own properties and methods for accessing individual elements of the node list.
As you can see, one of these properties is the “Count” property, used to obtain the number of child nodes, in order to iterate through them. Individual elements of the node list can be accessed in the same manner that you would access individual elements of an array. Each element in the XmlNodeList object returns a XmlNode object, which puts us back on familiar territory - the XmlNode object’s standard “Name” property can now be used to access information about the node.
The process is then repeated for each of these XmlNode objects - a check for further children, a retrieved XmlNodeList object, a loop iterating through the child nodes - until the end of the document tree is reached.
When Laziness Is A Virtue
In the example above, I’ve manually written code to handle each level of the tree for illustrative purposes - however, in a production environment, doing this is pure insanity, especially since an XML document can have any number of nested levels. A far more professional approach would be to write a recursive function to automatically iterate through the document tree - this results in cleaner, more readable code, and it’s also much, much easier to maintain.
<%@ Page Language="C#"%>
<%@ import namespace="System.Xml"%>
<html>
<head>
<script runat="server">
// keep track of the tabs
int intTabCounter = 0;
// function to format the tree with indented levels
void FormatTree (int intTabCounter) {
for(int j = 1; j < intTabCounter; j++) {
output.Text += "  ";
}
}
// function to obtain node information
void NodeDetails(XmlNode objNode) {
XmlNodeType objNodeType = objNode.NodeType;
// check if this node is an element
if(objNode.NodeType == XmlNodeType.Element) {
FormatTree(intTabCounter);
output.Text += "Element: " + objNode.Name + "<br/>";
// get the list of children
XmlAttributeCollection objNodeAttributes = objNode.Attributes;
// loop through the attributes of the element
for(int innercount = 0; innercount < objNodeAttributes.Count; innercount++) {
FormatTree(intTabCounter);
output.Text += "Attribute: " + objNodeAttributes[innercount].Name + " = " + objNodeAttributes[innercount].InnerText +"<br />";
}
} else if(objNode.NodeType == XmlNodeType.Text) {
// check if text node and print value
if (objNode.Value.Trim() != ""){
FormatTree(intTabCounter);
output.Text += "Character data: " + objNode.Value.Trim() + "<br/>";
}
} else if (objNode.NodeType == XmlNodeType.Comment) {
// check if comment node and print value
if (objNode.Value.Trim() != ""){
FormatTree(intTabCounter);
output.Text += "Comment: " + objNode.Value.Trim() + "<br/>";;
}
}
// get the list of child nodes
XmlNodeList objChildren = objNode.ChildNodes;
// loop through the nodes
for(int count = 0; count < objChildren.Count; count++) {
intTabCounter++;
// recursively call function to proceed to next level
NodeDetails(objChildren[count]);
intTabCounter--;
}
}
void Page_Load() {
// location of XML file
string strXmlDoc = "http://localhost:2121/xml/menu.xml";
// create an instance of XmlDocument object
XmlDocument objXmlDoc = new XmlDocument();
// load the XML document in the XmlDocument object
objXmlDoc.Load(strXmlDoc);
// get the root element of our Xml file
XmlElement objRootElem = objXmlDoc.DocumentElement;
// get more details about the node
NodeDetails(objRootElem);
}
</script>
</head>
<body>
<asp:label id="output" runat="server" />
</body>
</html>
And what’s the result?

Now, wasn’t that easier than manually writing code for each level of the document tree?
This should be easily understandable if you’re familiar with the concept of recursion. Most of the work happens in the NodeDetails() function, which now includes additional code to iterate through the different levels of the document tree automatically, and to make intelligent decisions about what to do with each node type found.
<%
// check if this node is an element
if(objNode.NodeType == XmlNodeType.Element) {
FormatTree(intTabCounter);
output.Text += "Element: " + objNode.Name + "<br/>";
// get the list of children
XmlAttributeCollection objNodeAttributes = objNode.Attributes;
// loop through the attributes of the element
for(int innercount = 0; innercount < objNodeAttributes.Count; innercount++) {
FormatTree(intTabCounter);
output.Text += "Attribute: " + objNodeAttributes[innercount].Name + " = " + objNodeAttributes[innercount].InnerText +"<br />";
}
}
%>
If the current node is an element, the element name is printed to the browser using the “Name” property. Next, the function checks for element attributes - the “Count” property of the collection will let me know if the node has any attributes. If it does, the “for” loop does the rest of the job of navigating through the collection and retrieving each and every attribute associated with the element. The attributes are returned as an XmlAttributeCollection object using the “Attributes” property of the current node. Note the use of the “InnerText” property to access the value stored in each attribute.
<%
if(objNode.NodeType == XmlNodeType.Text) {
// check if text node and print value
if (objNode.Value.Trim() != ""){
FormatTree(intTabCounter);
output.Text += "Character data: " + objNode.Value.Trim() + "<br/>";
}
} else if (objNode.NodeType == XmlNodeType.Comment) {
// check if comment node and print value
if (objNode.Value.Trim() != ""){
FormatTree(intTabCounter);
output.Text += "Comment: " + objNode.Value.Trim() + "<br/>";;
}
}
%>
In a similar manner, it’s also possible to check for text nodes, comments and any other node type, and write code to process each type individually. The example above handles text nodes and comments, printing each one to the standard output device as they are encountered. Note that, again, the “Value” property is used to extract the raw value of the node.
Finally, once the node has been processed, it’s time to see if it has any children, and proceed to the next level of the tree if so.
<%
// get the list of child nodes
XmlNodeList objChildren = objNode.ChildNodes;
// loop through the nodes
for(int count = 0; count < objChildren.Count; count++) {
intTabCounter++;
// recursively call function to proceed to next level
NodeDetails(objChildren[count]);
intTabCounter--;
}
%>
In the event that the node does have children, the children are stored in a XmlNodeList object, and the NodeDetails() function is recursively called for each of these nodes. And so on, and so on, ad infinitum…or at least until the entire tree has been processed.
Finally, the very simple FormatTree() method checks the value of the tab counter to determine the current depth within the XML tree, and displays that many spaces in the output in a primitive attempt to represent the data as a tree.
<%
void FormatTree (int intTabCounter) {
for(int j = 1; j < intTabCounter; j++) {
output.Text += "  ";
}
}
%>
Obviously, this is just one illustration of the applications of the .NET XML parser. This is probably enough to get you started with simple applications.
A La Carte
How about printing out the menu in a neat little tabular format as shown below?
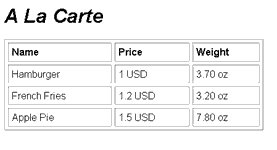
No sweat.
<%@ Page Language="C#"%>
<%@ import namespace="System.Xml"%>
<html>
<head>
<basefont face="Arial" />
<script runat="server">
// function to print the items in the menu
void printMenu(XmlNodeList objMenuItems) {
// loop through the items in the menu
for(int count = 0; count < objMenuItems.Count; count++) {
menu.Text += "<tr>";
// get the list of child nodes
XmlNodeList objMenuItemDetails = objMenuItems[count].ChildNodes;
// loop through the details of each node
for(int innercount = 0; innercount < objMenuItemDetails.Count; innercount++) {
XmlNode objMenuItemDetail = objMenuItemDetails[innercount];
menu.Text += "<td>" + objMenuItemDetail.InnerText;
// fetch attributes if available
XmlAttributeCollection objMenuItemDetailAttr = objMenuItemDetail.Attributes;
// loop through the attributes collection
for(int attrcount = 0; attrcount < objMenuItemDetailAttr.Count; attrcount++) {
menu.Text += " " + objMenuItemDetailAttr[attrcount].InnerText;
}
menu.Text += "</td>";
}
menu.Text += "</tr>";
}
}
void Page_Load() {
// store location of XML file
string strXmlDoc = "http://localhost:2121/xml/menu.xml";
// create instance of XmlDocument object
XmlDocument objXmlDoc = new XmlDocument();
// load the XML document into the XmlDocument object
objXmlDoc.Load(strXmlDoc);
// use the GetElementsByTagName() method
// to drill directly to items in menu
XmlNodeList objMenuItems = objXmlDoc.GetElementsByTagName("item");
// iterate over the nodes
// print out the menu items
printMenu(objMenuItems);
}
</script>
</head>
<body>
<h1 style="font-style:italic">A La Carte</h1>
<table width="55%" cellpadding="5" cellspacing="5" border="1">
<!-- header row -->
<tr>
<td><b>Name<b></td>
<td><b>Price</b></td>
<td><b>Weight</b></td>
</tr>
<asp:label id="menu" runat="server" />
</table>
</body>
</html>
Unlike previous example, where I started traversing the XML document from the root element, I’ve taken a shortcut this time - the GetElementsByTagName() method of the XmlDocument object, which allows me to go straight to a particular element in the DOM tree.
Once I have a list of the <item>s in an XmlNodeList object, it is the responsibility of my new printMenu() function to drill down further and print the data to the browser. In fact, if you take a closer look at this function, you will notice that I have used the properties and methods I showed you earlier to get the desired output.
Linking Out
That’s about it for this tutorial on parsing XML using the DOM. Over the last few pages, I gave you a quick introduction to one of the most important classes available in the .NET framework for working with XML - the XmlDocument object.
As demonstrated in the multiple examples listed above, this XmlDocument object is designed to read an XML file, build a tree to represent the structures found within it, and expose object methods and properties to manipulate them. Each example demonstrated the concept of nodes, and how you can use the DOM to traverse an XML document right from the root element to any child node at any depth. And if any of the nodes are associated with attributes, the XmlAttributeCollection object exposes the properties and methods needed to access them.
If you’d like to read more about parsing XML with the DOM, take a look at the following links:
The W3C’s DOM page, at http://www.w3.org/DOM/
The XML Document Object Model on MSDN, at http://msdn.microsoft.com/library/default.asp?url=/library/en-us/cpguide/html/cpconXMLDocumentObjectModelDOM.asp
A JavaScript view of the DOM, at https://www.melonfire.com/archives/trog/article/rough-guide-to-the-dom-part-1
Until next time…see ya!
Note: Examples are illustrative only, and are not meant for a production environment. Melonfire provides no warranties or support for the source code described in this article. YMMV!
This article was first published on 12 Dec 2003.