Onward Ho
You already know that an XML document may be either “well-formed” or “valid”.
A well-formed document is one which meets the specifications laid down in the XML recommendation - that is, it follows the rules for element and attribute names, contains all essential declarations, and has properly-nested elements.
A valid document is one which, in addition to being well-formed, adheres to the rules laid out in a document type definition (DTD) or XML Schema. By imposing some structure on an XML document, a DTD makes it possible for documents to conform to some standard rules, and for applications to avoid nasty surprises in the form of incompatible or invalid data.
DTDs and XML Schemas are essential when managing a large number of XML documents, as they immediately make it possible to apply a standard set of rules to different documents and thereby demand conformance to a common standard. However, for smaller, simpler documents, a DTD can often be overkill, adding substantially to download and processing time.
Now, what does this have to do with the XmlTextReader class I discussed in so much detail in the last segment of this tutorial? Nothing, really. You see, while the class does throw up errors if your XML document isn’t well-formed, it does not support validation against a DTD, XDR or XSD Schema. If you need to validate your XML file before processing it, you need to know its close cousin, the XmlValidatingReader object, which is derived from the same abstract XMLReader parent class. And then, once you know how to perform validation, you also need to know how to handle validation errors - which is why this article also includes a simple example that uses built-in exception handling mechanisms to trap errors that the Reader may come across.
Let’s get started!
Returning To The Library
I’ll explain how the XMLValidatingReader works by again referring to the sample XML instance created in the first part of this article. In case you don’t remember what it looked like, here it is again:
<?xml version='1.0'?>
<library xsi:noNamespaceSchemaLocation="library.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" >
<book id="MFRE001">
<title>XML and PHP</title>
<author>Vikram Vaswani</author>
<description>Learn to manage your XML data with PHP</description>
<price currency="USD">24.95</price>
</book>
<book id="MFRE002">
<title>MySQL - The Complete Reference</title>
<author>Vikram Vaswani</author>
<description>Learn everything about this open source database</description>
<price currency="USD">45.95</price>
<stock>1000</stock>
</book>
</library>
The only major difference in this version of the XML file is the introduction of the “xsi:noNamespaceSchemaLocation” attribute. For the uninformed, this holds the location of the Schema against which this document is to be validated.
And here’s the XML Schema against which the XML document listed above was originally built:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="library" type="LibraryType"/>
<xsd:complexType name="LibraryType">
<xsd:sequence maxOccurs="unbounded">
<xsd:element name="book" type="BookType"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="BookType">
<xsd:sequence>
<xsd:element name="title" type="xsd:string" />
<xsd:element name="author" type="xsd:string" />
<xsd:element name="description" type="xsd:string" />
<xsd:element name="price">
<xsd:complexType>
<xsd:simpleContent>
<xsd:extension base="xsd:decimal">
<xsd:attribute name="currency" type="xsd:string" />
</xsd:extension>
</xsd:simpleContent>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
<xsd:attribute name="id" type="xsd:string" />
</xsd:complexType>
</xsd:schema>
Now for the glue that binds them. Consider the following ASP.NET code, which validates the XML document instance against the XML Schema above:
<%@ Page Language="C#" Debug="true" %>
<%@ Import namespace="System.Xml"%>
<%@ Import namespace="System.Xml.Schema"%>
<html>
<head>
<script runat="server">
Boolean blnValidationSuccess = true;
void Page_Load() {
// define variables
string strXmlFile = "http://localhost:2121/xmlpull/library.xml";
// initialize the XML readers
XmlTextReader objXmlTxtRdr = new XmlTextReader(strXmlFile);
XmlValidatingReader objXmlValRdr = new XmlValidatingReader(objXmlTxtRdr);
// set the validation type
objXmlValRdr.ValidationType = ValidationType.Schema;
// set the validation event handler
objXmlValRdr.ValidationEventHandler += new ValidationEventHandler (ValidationMonitor);
// show some status messages
output.Text = "Validating file: <b>" + strXmlFile.ToString() + "</b>";
// read XML data
while (objXmlValRdr.Read()){}
output.Text += "<br />Validation <b>" + (blnValidationSuccess == true ? "successful" : "failed") + ".</b>";
objXmlValRdr.Close();
objXmlTxtRdr.Close();
}
// display validation errors
void ValidationMonitor (object sender, ValidationEventArgs args)
{
blnValidationSuccess = false;
output.Text += "<br />Validation Error: <i>" + args.Message + "</i>";
}
</script>
</head>
<body>
<asp:label id="output" runat="server"/>
</body>
</html>
If you were to test this code using the “library.xml” file shown above, the XML document instance should pass the validation tests with flying colours:
Validating file: http://localhost:2121/xmlpull/library.xml
Validation successful.
But look what happens if you add a new, unwanted element to the document instance:
<?xml version='1.0'?>
<library>
<book id="MFRE001">
<title>XML and PHP</title>
<author>Vikram Vaswani</author>
<description>Learn to manage your XML data with PHP</description>
<price currency="USD">24.95</price>
</book>
<book id="MFRE002">
<title>MySQL - The Complete Reference</title>
<author>Vikram Vaswani</author>
<description>Learn everything about this open source database</description>
<price currency="USD">45.95</price>
<inventory>12</inventory>
</book>
</library>
The XML Schema definition does not allow the XML author to add this new <inventory> element. That’s why you’ll see the following output when you reload the example in the browser:
Validating file: http://localhost:2121/xmlpull/library.xml
Validation Error: The element 'book' has invalid child element 'inventory'. An error occurred at http://localhost:2121/xmlpull/library.xml, (15, 4).
Validation Error: The 'inventory' element is not declared. An error occurred at http://localhost:2121/xmlpull/library.xml, (15, 4).
Validation failed.
Notice that the error message explicitly highlights the rogue <inventory> element in the XML file.
Now, let’s take a closer look at how this code works. It all starts with the definition of a flag variable to track the validation process.
<%
Boolean blnValidationSuccess = true;
%>
This is followed by the definition of the object required for our example. Here, I need to first initialize a plain-vanilla XmlTextReader object, and then pass this object as a parameter to the new XmlValidatingReader object, as shown below:
<%
// initialize the XML readers
XmlTextReader objXmlTxtRdr = new XmlTextReader(strXmlFile);
XmlValidatingReader objXmlValRdr = new XmlValidatingReader(objXmlTxtRdr);
%>
Next, I have defined the mechanism to use when validating the XML - in this case, an XML Schema. This is done via the “ValidationType” property of the XmlValidatingReader object:
<%
// set the validation type
objXmlValRdr.ValidationType = ValidationType.Schema;
%>
You can set the “ValidationType” property of the XmlValidatingReader object to any one of the following:
“ValidationType.None” - no validation is required
“ValidationType.Auto” - search for a file automatically; if available, carry out validation
“ValidationType.DTD” - perform validation using a DTD
“ValidationType.XDR” - perform validation using a XDR
“ValidationType.Schema” - perform validation using an XML Schema
While the validator is checking the XML document against the Schema, it generates an event if it encounters an error. Therefore, it’s a good idea to define an event handler to trap this event and take appropriate action when it occurs. In this example, I’ve defined an event handler function named ValidationMonitor(), and associated it with the object via its “ValidationEventHandler property”:
<%
// set the validation event handler
objXmlValRdr.ValidationEventHandler += new ValidationEventHandler (ValidationMonitor);
void ValidationMonitor (object sender, ValidationEventArgs args)
{
blnValidationSuccess = false;
output.Text += "<br />Validation Error: <i>" + args.Message + "</i>";
}
%>
Notice how the “Message” property of the object is used to display a user-friendly error message in the browser.
Finally, assuming no errors in validation, you can iterate over the document and process the XML inside it with the Read() method I showed you in the previous article. Here, the Read() loop is an empty block because I didn’t really want to process the data in the file, just validate it to show you how it was done.
<%
// read XML data
while (objXmlValRdr.Read()) {
}
output.Text += "<br />Validation <b>" + (blnValidationSuccess == true ? "successful" : "failed") + ".</b>";
%>
The example closes with a check on the “blnValidationSuccess” variable, displaying the appropriate outcome of the validation process to the user in the browser.
To DTD Or Not To DTD
Legacy is bitter reality and so, while XML Schemas are the way forward as far as validation is concerned, don’t be surprised when you come across a DTD or two in the XML framework that you are using. In such situations, you’ll also need to know how you can use a DTD to validate an XML document instance.
Here’s the updated XML file - notice it now includes a reference to a DTD instead of an XML Schema:
<?xml version='1.0'?>
<!DOCTYPE library SYSTEM "library.dtd">
<library>
<book id="MFRE001">
<title>XML and PHP</title>
<author>Vikram Vaswani</author>
<description>Learn to manage your XML data with PHP</description>
<price currency="USD">24.95</price>
</book>
<book id="MFRE002">
<title>MySQL - The Complete Reference</title>
<author>Vikram Vaswani</author>
<description>Learn everything about this open source database</description>
<price currency="USD">45.95</price>
</book>
</library>
This brings us to the actual beast - the “library.dtd” DTD file:
<!ELEMENT library (book+)>
<!ELEMENT book (title,author,description,price)>
<!ATTLIST book id CDATA #REQUIRED>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT description (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ATTLIST price currency CDATA #REQUIRED>
A close look at this file and you will see that it describes the structure of the XML document instance fairly well. Of course, in between all the element and attributes are quaint symbols and keywords that will make sense only to DTD experts (if you don’t belong to that elite group, you can start with the reference links provided at the end of this article).
And to complete this jigsaw, we have the ASP.NET code that uses the XmlValidatingReader object to tst the XML document instance against the DTD, as shown below:
<%@ Page Language="C#" Debug="true" %>
<%@ Import namespace="System.Xml"%>
<%@ Import namespace="System.Xml.Schema"%>
<html>
<head>
<script runat="server">
Boolean blnValidationSuccess = true;
void Page_Load() {
// define variables
string strXmlFile = "http://localhost:2121/xmlpull/library.xml";
// initialize the XML readers
// and set the ValidationType
XmlTextReader objXmlTxtRdr = new XmlTextReader(strXmlFile);
XmlValidatingReader objXmlValRdr = new XmlValidatingReader(objXmlTxtRdr);
// set the validation type
objXmlValRdr.ValidationType = ValidationType.DTD;
// set the validation event handler
objXmlValRdr.ValidationEventHandler += new ValidationEventHandler (ValidationMonitor);
// some output
output.Text = "Validating file: <b>" + strXmlFile.ToString() + "</b><br>";
// read XML data
while (objXmlValRdr.Read()){
String strSpaces;
// only process the elements, ignore everything else
if(objXmlValRdr.NodeType==XmlNodeType.Element) {
// reset the variable for a new node
strSpaces = "";
for(int count = 1; count <= objXmlValRdr.Depth; count++) {
strSpaces += "===";
}
output.Text += strSpaces + "=> " + objXmlValRdr.Name + "<br/>";
}
}
output.Text += "Validation <b>" + (blnValidationSuccess == true ? "successful" : "failed") + ".</b>";
objXmlValRdr.Close();
objXmlTxtRdr.Close();
}
// display the validation errors.
void ValidationMonitor (object sender, ValidationEventArgs args)
{
blnValidationSuccess = false;
output.Text += "<i>Validation Error: " + args.Message + "</i><br>";
}
</script>
</head>
<body>
<asp:label id="output" runat="server"/>
</body>
</html>
When you test this code, you’ll see that the XML document instance is successfully validated against the “library.dtd” file:

Now, once again, let me spoil things by introducing a rogue <inventory> element into the XML:

As you can see, the XmlValidatingReader object is quick to complain about the presence of the unwanted <inventory> element on the basis of the definitions present in the accompanying “library.dtd” file.
So what makes this script click? To be frank, the code hasn’t changed much from my previous example. The major difference lies in the “ValidationType” property of the XMLValidatingReader object; I have updated it to use a DTD instead of an XML Schema, as shown below:
<%
// snip
// set the validation type
objXmlValRdr.ValidationType = ValidationType.DTD;
// snip
%>
And to make things more interesting, I have added some code to the Read() function to prove that you need not leave it blank - a “while” loop now prints the names of elements to the console:
<%
// snip
// read XML data
while (objXmlValRdr.Read()) {
String strSpaces;
// only process the elements, ignore everything else
if(objXmlValRdr.NodeType == XmlNodeType.Element) {
// reset the variable for a new node
strSpaces = "";
for(int count = 1; count <= objXmlValRdr.Depth; count++) {
strSpaces += "===";
}
output.Text += strSpaces + "=> " + objXmlValRdr.Name + "<br/>";
}
}
// snip
%>
It is interesting to note here that the XMLValidatingReader will continue to read the XML data even if it encounters an error - which is why it becomes critical to ensure that you devise your very own escape route to get out of erroneous situations.
Of Nodes And Trees
Now, you’ve already seen two of the three built-in objects based on the core XmlReader object - the XmlTextReader and XmlValidatingReader objects. This leaves us with the third and final object in this family to deal with: the XmlNodeReader object.
The XmlNodeReader class allows you to read data from any node of a DOM tree present in memory. Now you may, as I did initially, question the rationale behind having a reader for such a specific requirement - after all, you can easily use the method and properties of the XmlDocument object to parse the file. But it’s important to remember that DOM parsing is a processor-intensive task; therefore, using an XmlReader object (which is faster and not as resource-hungry as the regular DOM parser) can produce better results in some cases.
Second, it is not wise to assume that your application will always receive XML data in the form of a flat file or an XML data stream. XML data might even come to you in the form of a fragment of DOM tree. In such a scenario, it makes sense to use the XmlNodeReader object to read the contents of the node because of its speed and efficient performance.
Enough talk! Take a look at an example that uses the XmlNodeReader object.
<%@ Page Language="C#"%>
<%@ import namespace="System.Xml"%>
<html>
<head>
<script runat="server">
void Page_Load() {
// define some variables
string strXmlFile = "http://localhost:2121/xmlpull/library.xml";
// create an instance of the XmlDocument object
XmlDocument objXmlDoc = new XmlDocument();
// load an XML file into the XmlDocument object
objXmlDoc.Load(strXmlFile);
// load the NodeList object with the nodes required
XmlNodeList objNodeList = objXmlDoc.GetElementsByTagName("book");
// loop through the node list
// for each node, create an XmlNodeReader object
// to read the XML data from the file
foreach(XmlNode myNode in objNodeList) {
XmlNodeReader objXmlRdr = new XmlNodeReader(myNode);
ReadXmlNode(objXmlRdr);
objXmlRdr.Close();
}
}
void ReadXmlNode(XmlNodeReader objXmlRdr) {
string strSpaces = "";
while(objXmlRdr.Read()) {
// only process the elements
if(objXmlRdr.NodeType==XmlNodeType.Element) {
// reset the variable for a new node
strSpaces = "";
for(int count = 1; count <= objXmlRdr.Depth; count++) {
strSpaces += "===";
}
output.Text += strSpaces + "=> " + objXmlRdr.Name + "<br/>";
}
}
}
</script>
</head>
<body>
<asp:label id="output" runat="server" />
</body>
</html>
This example is pretty straightforward. First, I have loaded the XML file into an XMLDocument object with the Load() method. I have then drilled down to the node of interest with the convenient GetElementsByTagName() method, which returns an XmlNodeList object that I can iterate over using a “foreach” loop, as shown below.
Now, each item in the XmlNodeList collection is an XmlNode object that can easily be used to create an instance of the XmlNodeReader object, the object that I’m interested in here. Since there will be multiple nodes resulting from this process, it make sense to place the corresponding code in a separate function which can be invoked repeatedly; hence the ReadXmlNode() function in the example above. Take a close look at this function, and you’ll see that there isn’t much difference between the method and properties of the XmlNodeReader object and the XmlTextReader object (the main difference lies in the source of the XML data they are capable of accepting)
Playing Catch
To err is human - which is why it’s imperative that you include some mechanism in your ASP.NET code to handle errors that come up during script execution. And the next example does just that, using the ever-popular “try-catch” mechanism to trap any errors that might arise. Take a look:
<%@ Page Language="C#"%>
<%@ import namespace="System.Xml"%>
<html>
<head>
<script runat="server">
void Page_Load() {
// create the XML Reader object
XmlTextReader objXmlRdr = null;
// start the "try" block
try {
// location of XML file
string strXmlFile = "http://localhost:2121/xmlpull/library.xml";
String strSpaces;
// create an instance of the XmlTextReader object
objXmlRdr = new XmlTextReader(strXmlFile);
objXmlRdr.WhitespaceHandling=WhitespaceHandling.None;
while(objXmlRdr.Read()) {
// only process the elements, ignore everything else
if(objXmlRdr.NodeType==XmlNodeType.Element) {
strSpaces = "";
for(int count = 1; count <= objXmlRdr.Depth; count++) {
strSpaces += "===";
}
output.Text += strSpaces + "=> " + objXmlRdr.Name + "<br/>";
}
}
} catch (XmlException e) {
output.Text = "An XML Exception occurred: " + e.Message;
} catch (Exception e) {
output.Text = "A General Exception occurred: " + e.Message;
} finally {
// close the XMLReader object
// if it exists
if(objXmlRdr != null) {
objXmlRdr.Close();
}
}
}
</script>
</head>
<body>
<asp:label id="output" runat="server" />
</body>
</html>
If all goes well, the output shows the tree structure of the XML document instance. But now, introduce an deliberate error by deleting the “library.xml” file and look what happens:
A General Exception occured: The remote server returned an error: (404) Not
Found.
Notice how the script take note of the absence of the XML file and displays a polite little message informing the user about the error.
Here’s what you’d see if you didn’t have an error-handling mechanism in place:
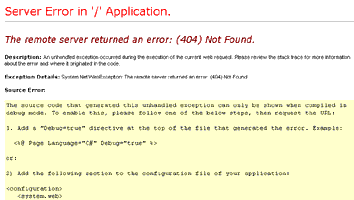
Not a pleasant sight at all!
Let’s try another error - “forget” to close the <library> element at the end of the file (thereby creating an XML document instance that is not well-formed) and look how the exception-handling mechanism reacts:
An XML Exception occurred: This is an unexpected token. The expected token is 'EndElement'. Line 15, position 3.
Most of the magic here lies in the “try-catch-finally” block, which does all the dirty work.
<%
// snip
// start the "try" block
try {
// process the XML file
// snip
} catch (XmlException e) {
output.Text = "An XML Exception occurred: " + e.Message;
} catch (Exception e) {
output.Text = "A General Exception occurred: " + e.Message;
} finally {
// close the XMLReader object
// if it exists
if(objXmlRdr != null) {
objXmlRdr.Close();
}
}
// snip
%>
First, you place all the code that processes the XML file - creating the XmlTextReader object, loading and reading the XML file and so on - in the “try” block.
This is followed by two “catch” blocks, one to handle an XmlException (these occur if something is wrong with the XML file itself) and another to handle any general Exception (such as a missing file).
Finally (pun intended), the “finally” block, which contains code that will always execute at the end of the “try” block (even if an exception takes place). This is the place for the code that closes objects and frees up vital system resources.
Linking Out
And that’s about all I have. At the beginning of this two-part tutorial, I told you that the .NET Framework came with three important classes derived from the XMLReader abstract class. I started with the most-used of these, the XMLTextReader class, and showed you how to use it to process elements, attributes and the data within them.
Today, the second part of this two-part series began with a simple example showing you how to validate an XML document against a XML Schema before processing it. I also showed you how to do the same thing with a DTD instead of a Schema, something that might happen on older legacy systems. This was followed by an introduction to the third member of this interesting set of classes, the XMLNodeReader class, and an example demonstrating its use. Finally, to wrap things up, I concluded by explaining how to handle errors when using a .NET XMLReader object to read XML files.
To learn more, consider visiting the following links:
Reading XML with the XmlReader, at http://msdn.microsoft.com/library/default.asp?url=/library/en-us/cpguide/html/cpconreadingxmlwithxmlreader.asp
The Fundamentals of DTD Design, at https://www.melonfire.com/archives/trog/article/the-fundamentals-of-dtd-design
Understanding XML Schema, at https://www.melonfire.com/archives/trog/article/understanding-xml-schema
A Better Way to Parse XML Documents in .NET, at http://builder.com.com/5102-6373-1044772.html
Comparing XmlReader to SAX Reader, at http://msdn.microsoft.com/library/default.asp?url=/library/en-us/cpguide/html/cpconcomparingxmlreadertosaxreader.asp
See you soon!
Note: Examples are illustrative only, and are not meant for a production environment. Melonfire provides no warranties or support for the source code described in this article. YMMV!
This article was first published on 30 Jan 2004.