Information Is Power (Or Is It?)
The nice thing about the Internet is that there’s so much information on it. The bad thing about the Internet is that there’s so much information on it.
This might seem a little cliched, but it’s true - the Web is rich in information, but poor in the tools needed to index and search it. Google’s (http://www.google.com/) doing a great job of fixing this problem, but it’s still limited largely to collating and indexing published content. If, for example, you’re looking for the email address of Sam Jones, who you know works somewhere in Long Beach with Rough Rubber Shoes, or the telephone number of your great-grand-uncle Josh, who moved to New York a few years back and was never heard from again, you’re outta luck - Google can’t help you, and neither can any of the other search engines out there.
What would be ideal in this situation is an Internet version of your local telephone directory, a public database of users and their affiliations, locations and contact information that you could query at the click of a button. Something that made it possible to easily search for resources (users, computers, businesses) by different attributes, that was universally accessible, and that was versatile enough to be used for different applications.
Something like LDAP.
Of Needles And Haystacks
Let’s start with the basics: what the heck is LDAP anyhoo?
The acronym LDAP stands for Lightweight Directory Access Protocol, which, according to the official specification at http://www.ietf.org/rfc/rfc2251.txt, is a protocol “designed to provide access to the X.500 Directory while not incurring the resource requirements of the Directory Access Protocol (DAP) […] specifically targeted at simple management applications and browser applications that provide simple read/write interactive access to the X.500 Directory, and is intended to be a complement to the DAP itself”.
Yup, it didn’t make sense to me either.
Before you can understand LDAP, you need to first understand what a “directory service” is. A directory service is exactly what it sounds like - a publicly available database of structured information. The most common example of a directory service is your local Yellow Pages - it contains names, addresses and contact numbers of different businesses, structured by business category, all indexed in a manner that is easily browseable or searchable.
Like ice-cream, directory services come in many flavours. They may be local to a specific organization (the corporate phone book) or more global in scope (a countrywide Yellow Pages). They can contain different types of information, ranging from employee names, phone numbers and email addresses to domain names and their corresponding IP addresses They can exist in different forms and at different locations, either as a single electronic database within an organization’s internal network or as a series of inter-connected databases existing at different geographical locations on a corporate extranet or the global Internet. Despite these differences, however, they all share certain common attributes: structured information, powerful browsing and search capabilities, and - in the case of distributed directories - inter-cooperation between the different pieces of the database.
Now, obviously, organizing information neatly in a directory is only part of the puzzle - in order for it to be useful, you need a way to get it out. If you’re using the local phone book, getting information out it as simple as flipping to the index, locating the category of interest, and opening it to the appropriate page. If you’re using an electronic, globally distributed directory service, however, you need something a little more sophisticated.
That’s where LDAP comes in.
Looking For Answers
Put very simply, LDAP is a protocol designed to allow quick, efficient searches of directory services. Built around Internet technologies, LDAP makes it possible to easily update and query directory services over standard TCP/IP connections, and includes a host of powerful features, including security, access control, data replication and support for Unicode.
LDAP is based largely on DAP, the Directory Access Protocol, which was designed for communication between directory servers and clients compliant to the X.500 standard. DAP is, however, fairly complex to implement and use, and is not suitable for the Web; LDAP is a simpler, faster alternative offering much of the same basic functionality without the performance overhead and deployment difficulties of DAP.
Since LDAP is built for a networked world, it is based on a client-server model. The system consists of one (or more) LDAP servers, which host the public directory service, and multiple clients, which connect to the server to perform queries and retrieve results. LDAP clients are today built into most common address book applications, including email clients like Microsoft Outlook and Qualcomm Eudora; however, since LDAP-compliant directories can store a diverse range of data (not just names and phone numbers), LDAP clients are also increasingly making an appearance in other applications.
Here’s a simplified diagram of how LDAP clients and servers work.

As you can see, the system above comprises three LDAP servers, each one handling a different section of the global directory. Client queries are either resolved immediately by the server to which they are directed (if that server has the requested information) or referred to another server for resolution. This redundancy between servers is what makes LDAP so suitable for the distributed nature of the Web - a single directory may be split across multiple servers in different locations and merged together at leveraged connection points to work as a single, unified database.
If you’re familiar with how the Internet Domain Name System (DNS) works, you’ll see numerous similarities between that model and the one described above - both are global directories split across multiple hosts, both contain built-in redundancy and replication features, and both include referral capabilities that make it possible to retrieve data that is not available locally from other hosts in the system.
Up A Tree
An LDAP directory is usually structured hierarchically, as a tree of nodes (the LDAP directory tree is sometimes referred to as the Directory Information Tree, or DIT). Each node represents a record, or “entry”, in the LDAP database.
An LDAP entry consists of numerous attribute-value pairs, and is uniquely identified by what is known as a “distinguished name” or “DN”. Consider the following diagram, which illustrates:
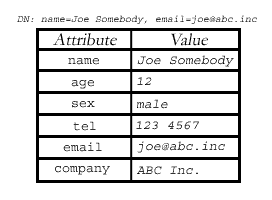
If you’re familiar with RDBMS, it’s pretty easy to draw an analogy here: an LDAP entry is analogous to a record, its attributes are the fields of that record, and a DN is a primary key that uniquely identifies each record.
Consider the following example of an LDAP entry, which might help make things clearer:
dn: [email protected], dc=melonfire, dc=com
objectclass: inetOrgPerson
cn: Joe
sn: Somebody
mail: [email protected]
telephoneNumber: 1 234 567 8912
This is an entry for a single person, Joe Somebody, who works at Melonfire. As you can see, the different components of the entry - name, email address, telephone number - are split into attribute-value pairs, with the entire record identified by a unique DN (the first line of the entry). Some of these attributes are required and some are optional, depending on the object class being used for the entry (more on this later); however, the entire set of data constitutes a single entry, or node, on the LDAP directory tree.
Wondering how a DN is created? Well, every entry in the directory tree has what is known as a “relative distinguished name” or “RDN”, which consists of one or more attribute-value pairs and must be unique at that level in the directory hierarchy. In the example above, for instance, the following are all valid RDNs for the entry:
cn=Joe
or
cn=Joe+sn=Somebody
or
cn=Joe+sn=Somebody+telephoneNumber=12345678912
or
In other words, there are no hard and fast rules as to which attributes of a particular entry should be used for the RDN; the LDAP model leaves this decision to the directory designer, simply specifying that the RDN of an entry must be such that it can uniquely identify that entry at that level in the DIT.
Now, since RDNs exist for each and every entry in the tree, the DN for any entry is formed by appending the RDNs of all the nodes between that entry and the root entry to each other. The DN thus makes it possible to easily locate any node in the directory tree, regardless of its location or depth in the hierarchy.
In order to better understand this, let’s take a simple example. Consider the following LDAP directory:
rdn: c=IN [dn:c=IN]
|
|
| --- rdn: o=Melonfire [dn:o=Melonfire,c=IN]
|
|
| --- rdn: ou=Executives [dn:ou=Executives,o=Melonfire,c=IN]
| |
| |
| | --- rdn: uid=sarah [dn:uid=sarah,ou=Executives,o=Melonfire,c=IN]
|
| --- rdn: ou=Worker Bees [dn:ou=Worker Bees,o=Melonfire,c=IN]
|
|
| --- rdn: uid=joe [dn:uid=joe,ou=Worker Bees,o=Melonfire,c=IN]
|
|
| --- rdn: uid=john [dn:uid=john,uid=joe,ou=Worker Bees,o=Melonfire,c=IN]
Now, in order to identify the node belonging to Joe Somebody - in other words, to obtain the DN for Joe Somebody’s entry - all you need to do is add up all the RDNs between that entry and the root of the tree. Doing this, you get
uid=joe,ou=Worker Bees,o=Melonfire,c=IN
In a similar manner, the DN for the node belonging to Sarah would be
uid=sarah,ou=Executives,o=Melonfire,c=IN
while the DN for the Melonfire node would be
o=Melonfire,c=IN
Since LDAP entries are arranged in a hierarchical tree, and since each node on the tree can be uniquely identified by a DN, the LDAP model lends itself well to sophisticated queries and powerful search filters. For example, I could restrict my search to a particular subset of the tree simply by specifying a different base for the query to begin from, or query only against specific attributes in the directory tree. Heck, I could even do both, and feel like a Real Programmer!
Treating Entries As Objects
So that (hopefully) takes care of understanding how LDAP entries are structured. Now, let’s go one level deeper, into the actual content of each entry.
Consider the following sample entry, shamelessly copied from the previous page:
dn: [email protected], dc=melonfire, dc=com
objectclass: inetOrgPerson
cn: Joe
sn: Somebody
mail: [email protected]
telephoneNumber: 1 234 567 8912
As you can see, this entry, which represents a person, consist of several attributes: common name (“cn”), surname (“sn”), email address (“mail”) and telephone number (“telephoneNumber”). Contrary to what you might think, these attributes have not been created by me willy-nilly - rather, they correspond to pre-existing definitions for what an LDAP entry must contain.
Where is this definition, and how does LDAP know what each entry should and should not contain, you ask wonderingly?
The answer lies in the second line of the entry above, in the “objectclass” attribute:
objectclass: inetOrgPerson
You see, LDAP is a very object-oriented beast. Every entry in an LDAP database is an instance of an object, and must therefore correspond to the rules laid down for the attributes of that object. These rules are very precise, clearly stating the allowed attribute names for an object, which attributes are mandatory and which are optional, and the allowed data types for the value of each attribute.
In the example above, the entry for Joe Somebody has been specified as an instance of the object class “inetOrgPerson”, and must therefore correspond to the rules laid down in the definition, or “schema”, for that class. Here it is:
# InetOrgPerson (RFC2798)
#
# Depends upon
# Definition of an X.500 Attribute Type and an Object Class to Hold
# Uniform Resource Identifiers (URIs) [RFC2079]
# (core.schema)
#
# A Summary of the X.500(96) User Schema for use with LDAPv3 [RFC2256]
# (core.schema)
#
# The COSINE and Internet X.500 Schema [RFC1274] (cosine.schema)
# carLicense
# This multivalued field is used to record the values of the license or
# registration plate associated with an individual.
attributetype ( 2.16.840.1.113730.3.1.1
NAME 'carLicense'
DESC 'RFC2798: vehicle license or registration plate'
EQUALITY caseIgnoreMatch
SUBSTR caseIgnoreSubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 )
# departmentNumber
# Code for department to which a person belongs. This can also be
# strictly numeric (e.g., 1234) or alphanumeric (e.g., ABC/123).
attributetype ( 2.16.840.1.113730.3.1.2
NAME 'departmentNumber'
DESC 'RFC2798: identifies a department within an organization'
EQUALITY caseIgnoreMatch
SUBSTR caseIgnoreSubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 )
# displayName
# When displaying an entry, especially within a one-line summary list, it
# is useful to be able to identify a name to be used. Since other attri-
# bute types such as 'cn' are multivalued, an additional attribute type is
# needed. Display name is defined for this purpose.
attributetype ( 2.16.840.1.113730.3.1.241
NAME 'displayName'
DESC 'RFC2798: preferred name to be used when displaying entries'
EQUALITY caseIgnoreMatch
SUBSTR caseIgnoreSubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15
SINGLE-VALUE )
# employeeNumber
# Numeric or alphanumeric identifier assigned to a person, typically based
# on order of hire or association with an organization. Single valued.
attributetype ( 2.16.840.1.113730.3.1.3
NAME 'employeeNumber'
DESC 'RFC2798: numerically identifies an employee within an organization'
EQUALITY caseIgnoreMatch
SUBSTR caseIgnoreSubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15
SINGLE-VALUE )
# employeeType
# Used to identify the employer to employee relationship. Typical values
# used will be "Contractor", "Employee", "Intern", "Temp", "External", and
# "Unknown" but any value may be used.
attributetype ( 2.16.840.1.113730.3.1.4
NAME 'employeeType'
DESC 'RFC2798: type of employment for a person'
EQUALITY caseIgnoreMatch
SUBSTR caseIgnoreSubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 )
# jpegPhoto
# Used to store one or more images of a person using the JPEG File
# Interchange Format [JFIF].
# Note that the jpegPhoto attribute type was defined for use in the
# Internet X.500 pilots but no referencable definition for it could be
# located.
attributetype ( 0.9.2342.19200300.100.1.60
NAME 'jpegPhoto'
DESC 'RFC2798: a JPEG image'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.28 )
# preferredLanguage
# Used to indicate an individual's preferred written or spoken
# language. This is useful for international correspondence or human-
# computer interaction. Values for this attribute type MUST conform to
# the definition of the Accept-Language header field defined in
# [RFC2068] with one exception: the sequence "Accept-Language" ":"
# should be omitted. This is a single valued attribute type.
attributetype ( 2.16.840.1.113730.3.1.39
NAME 'preferredLanguage'
DESC 'RFC2798: preferred written or spoken language for a person'
EQUALITY caseIgnoreMatch
SUBSTR caseIgnoreSubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15
SINGLE-VALUE )
# userSMIMECertificate
# A PKCS#7 [RFC2315] SignedData, where the content that is signed is
# ignored by consumers of userSMIMECertificate values. It is
# recommended that values have a `contentType' of data with an absent
# `content' field. Values of this attribute contain a person's entire
# certificate chain and an smimeCapabilities field [RFC2633] that at a
# minimum describes their SMIME algorithm capabilities. Values for
# this attribute are to be stored and requested in binary form, as
# 'userSMIMECertificate;binary'. If available, this attribute is
# preferred over the userCertificate attribute for S/MIME applications.
## OpenLDAP note: ";binary" transfer should NOT be used as syntax is binary
attributetype ( 2.16.840.1.113730.3.1.40
NAME 'userSMIMECertificate'
DESC 'RFC2798: PKCS#7 SignedData used to support S/MIME'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.5 )
# userPKCS12
# PKCS #12 [PKCS12] provides a format for exchange of personal identity
# information. When such information is stored in a directory service,
# the userPKCS12 attribute should be used. This attribute is to be stored
# and requested in binary form, as 'userPKCS12;binary'. The attribute
# values are PFX PDUs stored as binary data.
## OpenLDAP note: ";binary" transfer should NOT be used as syntax is binary
attributetype ( 2.16.840.1.113730.3.1.216
NAME 'userPKCS12'
DESC 'RFC2798: personal identity information, a PKCS #12 PFX'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.5 )
# inetOrgPerson
# The inetOrgPerson represents people who are associated with an
# organization in some way. It is a structural class and is derived
# from the organizationalPerson which is defined in X.521 [X521].
objectclass ( 2.16.840.1.113730.3.2.2
NAME 'inetOrgPerson'
DESC 'RFC2798: Internet Organizational Person'
SUP organizationalPerson
STRUCTURAL
MAY (
audio $ businessCategory $ carLicense $ departmentNumber $
displayName $ employeeNumber $ employeeType $ givenName $
homePhone $ homePostalAddress $ initials $ jpegPhoto $
labeledURI $ mail $ manager $ mobile $ o $ pager $
photo $ roomNumber $ secretary $ uid $ userCertificate $
x500uniqueIdentifier $ preferredLanguage $
userSMIMECertificate $ userPKCS12 )
)
Scary, huh?
Very fundamentally, a schema defines an object class, naming and describing the attributes that constitute that object, and also specifying the allowed data types for each. Don’t worry too much about it - schema decryption and design is strictly outside the scope of this tutorial, so you don’t need to lose sleep over the syntax and structure of the gobbledygook above. Simply note the last line,
objectclass ( 2.16.840.1.113730.3.2.2
NAME 'inetOrgPerson'
DESC 'RFC2798: Internet Organizational Person'
SUP organizationalPerson
STRUCTURAL
MAY (
audio $ businessCategory $ carLicense $ departmentNumber $
displayName $ employeeNumber $ employeeType $ givenName $
homePhone $ homePostalAddress $ initials $ jpegPhoto $
labeledURI $ mail $ manager $ mobile $ o $ pager $
photo $ roomNumber $ secretary $ uid $ userCertificate $
x500uniqueIdentifier $ preferredLanguage $
userSMIMECertificate $ userPKCS12 )
)
which lists the attributes required for any object instance claiming to belong to this class - the keyword MUST specifies the required attributes, the keyword MAY specifies the optional attributes and the keyword SUP specifies the parent of this class.
Which brings me, rather neatly, to inheritance.
The Sins Of The Fathers…
One of the nice things about object-oriented programming is inheritance - which means, simply, that you can take a pre-existing object and use it to spawn a child object which inherits all the properties of the parent, while simultaneously including any custom properties you may decide to give it. And your newly-created object can, in turn, serve as the base for yet another object, and so on ad infinitum…
In the LDAP world, all this means is that object definitions can be inherited, thereby freeing schema designers to concentrate on other, more important things. In the example above, for instance, you’ll see that the definition for the “inetOrgPerson” class does not include attributes for “cn” and “sn” - even though my original LDAP entry includes these attributes.
Why, you ask? Because the “inetOrgPerson” class also inherits some attributes from the “organizationalPerson” class
objectclass ( 2.5.6.7 NAME 'organizationalPerson'
DESC 'RFC2256: an organizational person'
SUP person STRUCTURAL
MAY ( title $ x121Address $ registeredAddress $ destinationIndicator $ preferredDeliveryMethod $ telexNumber $ teletexTerminalIdentifier $ telephoneNumber $ internationaliSDNNumber $ facsimileTelephoneNumber $ street $ postOfficeBox $ postalCode $ postalAddress $ physicalDeliveryOfficeName $ ou $ st $ l ) )
which, in turn, inherits some attributes (including the lost-but-now-found “cn” and “sn” attributes) from the “person” class.
objectclass ( 2.5.6.6 NAME 'person'
DESC 'RFC2256: a person'
SUP top STRUCTURAL
MUST ( sn $ cn )
MAY ( userPassword $ telephoneNumber $ seeAlso $ description ) )
In case you’re wondering, all these definitions are LDAP standards and come bundled with most LDAP servers; however, if you have the time (and necessary knowledge), LDAP also allows you to design your own schema definitions and include them in your object collection.
You can also apply more than one object definition to a single entry - consider the following hybrid:
dn: dc=melonfire, dc=com
objectclass: dcObject
objectclass: organization
dc: melonfire
o: Melonfire
In this case, I’ve said that the entry is an instance of the “dcObject” and “organization” classes. Since I’ve used more than one object class, the final LDAP entry must be compliant with the rules specified in each of the referenced class definitions.
Now, while I’d love to go on and on about the theory behind LDAP, this is, sadly, all we have time for at the moment (it’s also all you really need to know about LDAP, unless you’re a geek with a penchant who likes calculating pi to the nineteenth digit). In the second part of this article, I’ll be putting all this theory to the test, using it to build a real, live LDAP-based address book for a small office. Make sure you come back for that!
Note: Examples are illustrative only, and are not meant for a production environment. Melonfire provides no warranties or support for the source code described in this article. YMMV!
This article was first published on 25 Feb 2003.