Opiate Of The Masses
If you’ve been following this column over the past few months, you’ve probably already picked up on the fact that I’m a big fan of MySQL, the free, open-source RDBMS. MySQL has a huge fan following all over the world - the site claims that over 30,000 copies of the software are downloaded every day by developers and users - and, with large corporate houses like SAP taking an interest in its future development, it’s quickly becoming a worthy alternative to commercial products.
Earlier versions of MySQL (the 3.23.x series) were pretty basic, as far as SQL databases go - they supported simple data creation and manipulation constructs like INSERT, UPDATE, DELETE and SELECT, and included support for fundamental things like comparison and logical operators, aggregate functions, indices, primary keys and sequences. However, they lacked support for more advanced features - transaction processing, subqueries, multi-table operations - focusing instead on delivering the basic set of services reliably and efficiently. MySQL 4.x, though, has shaken things up a little - its chock-full of new features (including all the items mentioned above), and promises to aggressively continue innovating and adding new capabilities to its already bulging feature-set.
One of the newest features in MySQL, and one of its most eagerly-anticipated ones, is subqueries. Subqueries have been on the MySQL wishlist for a while; they’ve finally made an appearance in MySQL 4.1, and, as someone who’s been playing with them for a little while, I can tell you that they’re pretty useful. Sadly, however, since the software is still under development, there isn’t too much information available at the moment on their full capabilities in the MySQL context.
That’s where this article comes in. Over this two-part tutorial, I will be introducing you to subqueries, which make it possible for you to do all kinds of creative things with your SQL queries. Regardless of whether you’ve a novice who’s never heard of subqueries before but are eager to find out how they can enrich your life, or someone who’s been tinkering with MySQL for a while (like me), I think you’ll find the next few pages interesting. So come on in, and let’s get started.
Sub-Zero Code
Subqueries, as the name suggests, are queries nested inside other queries. They make it possible to use the results of one query directly in the conditional tests or FROM clauses of other queries, and can substantially simplify the task of writing SQL-based applications, by reducing the number of application-level query statements to be executed in a given program.
Subqueries come in many shapes, sizes and forms. The most common one is a SELECT within a SELECT, such that the results of the inner SELECT serve as values for the WHERE clause of the outer SELECT. However, while this is certainly one of the most common uses of subqueries, it’s not the only one - as you’ll see, you can use subqueries in a number of other places, including within grouped result sets, with comparison and logical operators, with membership tests, in UPDATE and DELETE operations, and within a query’s FROM clause. They’re a very powerful tool - and properly used, they can let you perform some pretty amazing feats with SQL.
Before proceeding further, be warned that subqueries are still in an experimental stage, and are only available in MySQL 4.1 and above. If you’re using an older version of MySQL, the examples in this tutorial will not execute correctly. You can get yourself the latest version of the software, for both Windows and Linux platforms, on the very informative MySQL Web site, at http://www.mysql.com/
If you’re not already set up, get yourself a copy of MySQL, install and configure it (the installation documents that come with the binary archive for your platform will tell you how) and then flip the page to meet the tables I’ll be using in this tutorial.
Turning The Tables
Before we begin, a quick introduction to the tables I’ll be using throughout this tutorial seems to be in order. In order to explain subqueries, I’ll be using a fictitious company’s accounting database, which consists of the following four tables:
- The “services” table: The fictitious company under discussion offers customers a number of outsourced services, each of which is associated with a fee and has a unique service ID. This information is stored in a “services” table, which looks like this:
mysql> SELECT * FROM services;
+-----+------------------+---------+
| sid | sname | sfee |
+-----+------------------+---------+
| 1 | Accounting | 1500.00 |
| 2 | Recruitment | 500.00 |
| 3 | Data Management | 300.00 |
| 4 | Administration | 500.00 |
| 5 | Customer Support | 2500.00 |
| 6 | Security | 600.00 |
+-----+------------------+---------+
6 rows in set (0.16 sec)
- The “clients” table: The company also has a list of its current clients stored in a separate “clients” table. Each client is identified with a unique customer ID.
mysql> SELECT * FROM clients;
+-----+-----------------------------+
| cid | cname |
+-----+-----------------------------+
| 101 | JV Real Estate |
| 102 | ABC Talent Agency |
| 103 | DMW Trading |
| 104 | Rabbit Foods Inc |
| 110 | Sharp Eyes Detective Agency |
+-----+-----------------------------+
5 rows in set (0.00 sec)
- The “branches” table: Each customer may have one or more branch offices. The “branches” table lists the branch offices per customer, together with each branch’s location. Each branch has a description, a unique branch ID, and a foreign key reference to the customer ID.
mysql> SELECT * FROM branches;
+------+-----+--------------------------------+------+
| bid | cid | bdesc | bloc |
+------+-----+--------------------------------+------+
| 1011 | 101 | Corporate HQ | CA |
| 1012 | 101 | Accounting Department | NY |
| 1013 | 101 | Customer Grievances Department | KA |
| 1041 | 104 | Branch Office (East) | MA |
| 1042 | 104 | Branch Office (West) | CA |
| 1101 | 110 | Head Office | CA |
| 1031 | 103 | N Region HO | ME |
| 1032 | 103 | NE Region HO | CT |
| 1033 | 103 | NW Region HO | NY |
+------+-----+--------------------------------+------+
9 rows in set (0.01 sec)
- The “branches_services” table: Services supplied to each branch office are listed in this table, which contains pairs of branch IDs and service IDs (foreign keys into the “branches” and “services” table respectively).
mysql> SELECT * FROM branches_services;
+------+-----+
| bid | sid |
+------+-----+
| 1011 | 1 |
| 1011 | 2 |
| 1011 | 3 |
| 1011 | 4 |
| 1012 | 1 |
| 1013 | 5 |
| 1041 | 1 |
| 1041 | 4 |
| 1042 | 1 |
| 1042 | 4 |
| 1101 | 1 |
| 1031 | 2 |
| 1031 | 3 |
| 1031 | 4 |
| 1032 | 3 |
| 1033 | 4 |
+------+-----+
16 rows in set (0.11 sec)
The relationships between the various tables are best illustrated with the following diagram:
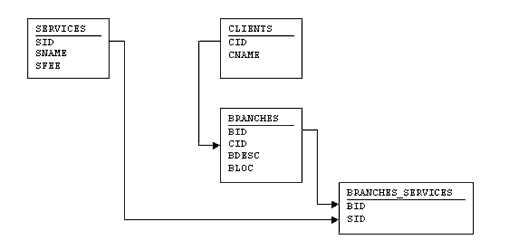
In order for you to try out the examples in this tutorial, you should recreate these tables in your development environment. Here are the SQL queries I used:
#
# Table structure for table `branches`
#
CREATE TABLE branches (
bid int(8) NOT NULL default '0',
cid tinyint(4) NOT NULL default '0',
bdesc varchar(255) NOT NULL default '',
bloc char(3) NOT NULL default ''
) TYPE=MyISAM CHARSET=latin1;
#
# Dumping data for table `branches`
#
INSERT INTO branches (bid, cid, bdesc, bloc) VALUES (1011, 101, 'Corporate HQ', 'CA');
INSERT INTO branches (bid, cid, bdesc, bloc) VALUES (1012, 101, 'Accounting Department', 'NY');
INSERT INTO branches (bid, cid, bdesc, bloc) VALUES (1013, 101, 'Customer Grievances Department', 'KA');
INSERT INTO branches (bid, cid, bdesc, bloc) VALUES (1041, 104, 'Branch Office (East)', 'MA');
INSERT INTO branches (bid, cid, bdesc, bloc) VALUES (1042, 104, 'Branch Office (West)', 'CA');
INSERT INTO branches (bid, cid, bdesc, bloc) VALUES (1101, 110, 'Head Office', 'CA');
INSERT INTO branches (bid, cid, bdesc, bloc) VALUES (1031, 103, 'N Region HO', 'ME');
INSERT INTO branches (bid, cid, bdesc, bloc) VALUES (1032, 103, 'NE Region HO', 'CT');
INSERT INTO branches (bid, cid, bdesc, bloc) VALUES (1033, 103, 'NW Region HO', 'NY');
#
# Table structure for table `branches_services`
#
CREATE TABLE branches_services (
bid int(8) NOT NULL default '0',
sid tinyint(4) NOT NULL default '0'
) TYPE=MyISAM CHARSET=latin1;
#
# Dumping data for table `branches_services`
#
INSERT INTO branches_services (bid, sid) VALUES (1011, 1);
INSERT INTO branches_services (bid, sid) VALUES (1011, 2);
INSERT INTO branches_services (bid, sid) VALUES (1011, 3);
INSERT INTO branches_services (bid, sid) VALUES (1011, 4);
INSERT INTO branches_services (bid, sid) VALUES (1012, 1);
INSERT INTO branches_services (bid, sid) VALUES (1013, 5);
INSERT INTO branches_services (bid, sid) VALUES (1041, 1);
INSERT INTO branches_services (bid, sid) VALUES (1041, 4);
INSERT INTO branches_services (bid, sid) VALUES (1042, 1);
INSERT INTO branches_services (bid, sid) VALUES (1042, 4);
INSERT INTO branches_services (bid, sid) VALUES (1101, 1);
INSERT INTO branches_services (bid, sid) VALUES (1031, 2);
INSERT INTO branches_services (bid, sid) VALUES (1031, 3);
INSERT INTO branches_services (bid, sid) VALUES (1031, 4);
INSERT INTO branches_services (bid, sid) VALUES (1032, 3);
INSERT INTO branches_services (bid, sid) VALUES (1033, 4);
#
# Table structure for table `clients`
#
CREATE TABLE clients (
cid tinyint(4) NOT NULL default '0',
cname varchar(255) NOT NULL default '',
PRIMARY KEY (cid)
) TYPE=MyISAM CHARSET=latin1;
#
# Dumping data for table `clients`
#
INSERT INTO clients (cid, cname) VALUES (101, 'JV Real Estate');
INSERT INTO clients (cid, cname) VALUES (102, 'ABC Talent Agency');
INSERT INTO clients (cid, cname) VALUES (103, 'DMW Trading');
INSERT INTO clients (cid, cname) VALUES (104, 'Rabbit Foods Inc');
INSERT INTO clients (cid, cname) VALUES (110, 'Sharp Eyes Detective Agency');
#
# Table structure for table `services`
#
CREATE TABLE services (
sid tinyint(4) NOT NULL default '0',
sname varchar(255) NOT NULL default '',
sfee float(6,2) NOT NULL default '0.00',
PRIMARY KEY (sid)
) TYPE=MyISAM CHARSET=latin1;
#
# Dumping data for table `services`
#
INSERT INTO services (sid, sname, sfee) VALUES (1, 'Accounting', '1500.00');
INSERT INTO services (sid, sname, sfee) VALUES (2, 'Recruitment', '500.00');
INSERT INTO services (sid, sname, sfee) VALUES (3, 'Data Management', '300.00');
INSERT INTO services (sid, sname, sfee) VALUES (4, 'Administration', '500.00');
INSERT INTO services (sid, sname, sfee) VALUES (5, 'Customer Support', '2500.00');
INSERT INTO services (sid, sname, sfee) VALUES (6, 'Security', '600.00');
Once you’ve got your tables created, flip the page and let’s start subquerying!
Back To Basics
You already know that you can obtain a complete list of all the records in a table with a simple SELECT * - for example, a list of all clients:
mysql> SELECT * FROM clients;
+-----+-----------------------------+
| cid | cname |
+-----+-----------------------------+
| 101 | JV Real Estate |
| 102 | ABC Talent Agency |
| 103 | DMW Trading |
| 104 | Rabbit Foods Inc |
| 110 | Sharp Eyes Detective Agency |
+-----+-----------------------------+
5 rows in set (0.22 sec)
You can also attach a join and a WHERE clause to the SELECT statement in order to filter the list of records down to only those matching specific criteria - for example, a list of all clients with branch offices in California only:
mysql> SELECT cname, bdesc, bloc FROM clients, branches WHERE clients.cid = branches.cid AND branches.bloc = 'CA';
+-----------------------------+----------------------+------+
| cname | bdesc | bloc |
+-----------------------------+----------------------+------+
| JV Real Estate | Corporate HQ | CA |
| Rabbit Foods Inc | Branch Office (West) | CA |
| Sharp Eyes Detective Agency | Head Office | CA |
+-----------------------------+----------------------+------+
3 rows in set (0.00 sec)
How about something a little more involved? Let’s say I need a list of all the branch offices belonging to “Rabbit Foods Inc”. Now, I could do this by running two SELECT queries, one after another, to first get the customer ID of “Rabbit Foods Inc”, and then using that ID (104) in another query to get the list of branch offices linked to that customer,
mysql> SELECT cid FROM clients WHERE cname = 'Rabbit Foods Inc';
+-----+
| cid |
+-----+
| 104 |
+-----+
1 row in set (0.17 sec)
mysql> SELECT bdesc FROM branches WHERE cid = 104;
+----------------------+
| bdesc |
+----------------------+
| Branch Office (East) |
| Branch Office (West) |
+----------------------+
2 rows in set (0.17 sec)
by equi-joining the “clients” and “branches” tables,
mysql> SELECT bdesc FROM branches, clients WHERE clients.cid = branches.cid AND clients.cname = 'Rabbit Foods Inc';
+----------------------+
| bdesc |
+----------------------+
| Branch Office (East) |
| Branch Office (West) |
+----------------------+
2 rows in set (0.22 sec)
or with a subquery.
mysql> SELECT bdesc FROM branches WHERE cid = (SELECT cid FROM clients WHERE cname = 'Rabbit Foods Inc');
+----------------------+
| bdesc |
+----------------------+
| Branch Office (East) |
| Branch Office (West) |
+----------------------+
2 rows in set (0.22 sec)
Thus, a subquery makes it possible to combine two or more queries into a single statement, and use the results of one query in the conditional clause of the other. Subqueries are usually regular SELECT statements, and are separated from their parent query by parentheses, as in the example above.
A subquery must return a single column of results, or else MySQL will not know how to handle the result set. Consider the following example, which demonstrates by having the subquery return a two-column result set:
mysql> SELECT bdesc FROM branches WHERE cid = (SELECT cid, cname FROM clients WHERE cname = 'Rabbit Foods Inc');
ERROR 1239: Cardinality error (more/less than 1 columns)
You can nest subqueries to any depth, so long as the basic rules above are followed. Consider the following example, which demonstrates by listing the services used by Sharp Eyes Detective Agency:
mysql> SELECT sname FROM services WHERE sid = (SELECT sid FROM branches_services WHERE bid = (SELECT bid FROM branches WHERE cid = (SELECT cid FROM clients WHERE cname = 'Sharp Eyes Detective Agency')));
+------------+
| sname |
+------------+
| Accounting |
+------------+
1 row in set (0.28 sec)
Branching Out
Subqueries are usually preceded by a conditional WHERE clause, which can contain any of the following comparison and logical operators:
| Operator | What It Means |
|---|---|
| = | values are equal |
| <> | values are unequal |
| <= | value on left is less than or equal to value on right |
| >= | value on left is greater than or equal to value on right |
| < | value on left is less than value on right |
| > | value on left is greater than value on right |
| BETWEEN | value on left lies between values on right |
| NOT | logical NOT |
| AND | logical AND |
| OR | logical OR |
In order to demonstrate, let’s say I wanted a list of all those customers with exactly two branch offices. First, I need to figure out a way to obtain the number of branch offices per customer,
mysql> SELECT cid, COUNT(bid) FROM branches GROUP BY cid;
+-----+------------+
| cid | count(bid) |
+-----+------------+
| 101 | 3 |
| 103 | 3 |
| 104 | 2 |
| 110 | 1 |
+-----+------------+
4 rows in set (0.27 sec)
and then filter out those with just two offices with a HAVING clause,
mysql> SELECT cid, COUNT(bid) FROM branches GROUP BY cid HAVING COUNT(bid) = 2;
+-----+------------+
| cid | count(bid) |
+-----+------------+
| 104 | 2 |
+-----+------------+
1 row in set (0.16 sec)
and then hand the client ID over to the “clients” table in order to get the client name.
mysql> SELECT cname FROM clients WHERE cid = 104;
+------------------+
| cname |
+------------------+
| Rabbit Foods Inc |
+------------------+
1 row in set (0.22 sec)
The following subquery will take care of the three steps above for me:
mysql> SELECT cname FROM clients WHERE cid = (SELECT cid FROM branches GROUP BY cid HAVING COUNT(bid) = 2);
+------------------+
| cname |
+------------------+
| Rabbit Foods Inc |
+------------------+
1 row in set (0.28 sec)
In this case, the inner query is executed first - this query takes care of grouping the branches by customer ID and counting the number of records (branch offices) in each group. Those customers which have exactly two branch offices can easily filtered out with a HAVING clause, and the corresponding customer IDs returned to the main query, which then maps the IDs into the customers table and returns the corresponding customer name.
How about selecting all those customers using the service with the maximum service fee?
mysql> SELECT cname, bdesc FROM clients, branches, branches_services, services WHERE services.sid = branches_services.sid AND clients.cid = branches.cid AND branches.bid = branches_services.bid AND sfee = (SELECT MAX(sfee) FROM services);
+----------------+--------------------------------+
| cname | bdesc |
+----------------+--------------------------------+
| JV Real Estate | Customer Grievances Department |
+----------------+--------------------------------+
1 row in set (0.01 sec)
Next up, HAVING clauses.
Having Your Code, And Eating It Too
You can use a subquery in a HAVING clause as well, and thereby use it as a filter for the groups created in the parent query. I’ll demonstrate by finding out which sites are using more than 50% of all available services.
mysql> SELECT bid FROM branches_services GROUP BY bid HAVING COUNT(sid) > (SELECT COUNT(*) FROM services)/2;
+------+
| bid |
+------+
| 1011 |
+------+
1 row in set (0.22 sec)
You can add a fast inner join to get the branch name and customer name as well if you like:
mysql> SELECT c.cid, c.cname, b.bid, b.bdesc FROM clients AS c, branches AS b, branches_services AS bs WHERE c.cid = b.cid AND b.bid = bs.bid GROUP BY bs.bid HAVING COUNT(bs.sid) > (SELECT COUNT(*) FROM services)/2;
+-----+----------------+------+--------------+
| cid | cname | bid | bdesc |
+-----+----------------+------+--------------+
| 101 | JV Real Estate | 1011 | Corporate HQ |
+-----+----------------+------+--------------+
1 row in set (0.28 sec)
Is it possible to get a list of branches using all available services? Sure!
mysql> SELECT branches.bid, COUNT(sid) FROM branches, branches_services WHERE branches.bid = branches_services.bid GROUP BY branches.bid HAVING COUNT(sid) = (SELECT COUNT(*) FROM services);
Empty set (0.04 sec)
And that’s quite right - if you look at the raw data, you’ll see that there are no individual branch offices using all available services. Maybe if I went up the totem pole a little and checked to see if there were any clients using all available services across their branch offices…
mysql> SELECT clients.cname FROM clients, branches, branches_services WHERE branches.bid = branches_services.bid AND branches.cid = clients.cid GROUP BY clients.cid HAVING COUNT(sid) = (SELECT COUNT(*) FROM services);
+----------------+
| cname |
+----------------+
| JV Real Estate |
+----------------+
1 row in set (0.01 sec)
Apples And Oranges
As you’ve seen on the previous page, subqueries and joins coexist very nicely - but why restrict yourself only to inner joins? You can use pretty much any kind of join in combination with a subquery - and with a little bit of creative thinking, you can use the synergy between the two to perform some very sophisticated queries.
For example, you already know that you can obtain a list of all clients which have no entry in the “branches” table with a left join, as below:
mysql> SELECT cname FROM clients LEFT JOIN branches ON clients.cid = branches.cid WHERE branches.bid IS NULL;
+-------------------+
| cname |
+-------------------+
| ABC Talent Agency |
+-------------------+
1 row in set (0.17 sec)
In this case, the query will retain all records on the left side of the join - the client list - and insert NULLs for every record on the right side - the branches - which does not meet the join condition. The end result? All clients without a branch office will be marked with a NULL value (which can then be isolated with an IS NULL test).
Another way to do this (and just so you know, I’m being deliberately perverse here because I want to demonstrate how joins can be used within subqueries) is to use a right join with a subquery.
mysql> SELECT cname FROM clients WHERE cid = (SELECT clients.cid FROM branches RIGHT JOIN clients ON clients.cid = branches.cid WHERE branches.bid IS NULL);
+-------------------+
| cname |
+-------------------+
| ABC Talent Agency |
+-------------------+
1 row in set (0.22 sec)
In this case too, all records on the right side of the join - the clients - will be retained and missing branch office records for each client will be marked with NULLs. The subquery will return the corresponding client IDs, which can then be mapped to the “customers” table for the human-readable client name.
It’s interesting to note that most of the time, subqueries can be written as joins, and vice-versa. Consider the following example, which lists the branch offices using the “Recruitment” service via a subquery,
mysql> SELECT bid FROM branches_services WHERE sid = (SELECT sid FROM services WHERE sname = 'Recruitment');
+------+
| bid |
+------+
| 1011 |
| 1031 |
+------+
2 rows in set (0.22 sec)
and this next one, which does the same thing using a join.
mysql> SELECT bs.bid FROM branches_services AS bs, services AS s WHERE s.sid = bs.sid AND s.sname = 'Recruitment';
+------+
| bid |
+------+
| 1011 |
| 1031 |
+------+
2 rows in set (0.17 sec)
More often than not, joins are faster than subqueries, because MySQL can optimize them better.
You can also write subqueries as self-joins, and vice-versa. Consider the following example, which lists all the branches in the same location as “JV Real Estate”’s corporate headquarters using a subquery,
mysql> SELECT bid, bdesc, bloc FROM branches WHERE bloc = (SELECT bloc FROM branches WHERE bid = 1101 AND cid = 110);
+------+----------------------+------+
| bid | bdesc | bloc |
+------+----------------------+------+
| 1011 | Corporate HQ | CA |
| 1042 | Branch Office (West) | CA |
| 1101 | Head Office | CA |
+------+----------------------+------+
3 rows in set (0.22 sec)
and this equivalent, which does the same thing using a self join.
mysql> SELECT table1.bid, table1.bdesc, table1.bloc FROM branches AS table1, branches AS table2 WHERE table2.bid = 1101 AND table2.cid = 110 AND table1.bloc = table2.bloc ;
+------+----------------------+------+
| bid | bdesc | bloc |
+------+----------------------+------+
| 1011 | Corporate HQ | CA |
| 1042 | Branch Office (West) | CA |
| 1101 | Head Office | CA |
+------+----------------------+------+
3 rows in set (0.16 sec)
And that’s about it for this introductory segment. Over the last few pages, I introduced you to subqueries, one of the most powerful and useful new features in MySQL 4.1, and showed you how you can use them to filter SQL result sets. I demonstrated how subqueries can be used in both the WHERE and HAVING clause of outer SELECT queries, both in combination with MySQL’s other comparison and logical operators and with MySQL’s aggregate functions and GROUP BY clauses. Finally, I demonstrated how subqueries and joins can be used in combination with one another, and how many subqueries can be rewritten as joins (and vice-versa).
That’s not all, though. Now that you (hopefully) know the basics, the second part of this tutorial will introduce you to more advanced uses of subqueries, including how to use them within a SELECT’s query’s FROM clause, with the IN operator and the EXISTS test, and with other MySQL data manipulation commands. All that and more, in the concluding segment of this article…so make sure you don’t miss it!
Note: Examples are illustrative only, and are not meant for a production environment. Melonfire provides no warranties or support for the source code described in this article. YMMV!
This article was first published on 18 Jul 2003.